
Pandasをつかって、Excelのデータを読み込む際に、セルの空白は欠損値(NaN)となってしまう。
まずエクセルで、シンプルなデータをつくってみよう〜
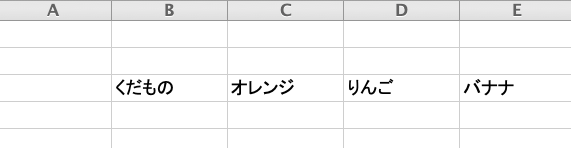
ファイル名を fruits.xlsxとして読み込む。
以下、Jupyter Notenookでの作業となるよ。
import pandas as pd
fruits = pd.read_excel(‘fruits.xlsx’)
fruits

excelの空白のセルはNaN(欠損値)として表示されてしまう。
dropna()メソッドをつかってみる。
fruits.dropna()

うっ、なんと、データがすべて削除されてしまった。
dropnaメソッドに引数を与えてみる。
fruits.dropna(how=’all’)

行のNaNは削除されたけれど、列のNaNが残ってしまう。
dropnaメソッドを繰り返す。
引数how=’allは列のNaNの削除、how=’all’,axis= 1は列の引数、
ちなみに列の引数はhow=’all’,axis= 0もいけたりする。
要はaxis=0は行、axis=1は列を指示するんだわ。
fruits.dropna(how=’all’).dropna(how=’all’,axis= 1)
