
ExcelからPandasに読み込むばあい、NaN(欠損値)の処理に手間取ってしまう。
きのうのブログでは、NaNが一列、一行の場合の処理の方法を書いてみた。
NaNが一列、一行の途中にある場合、どう処理したら良いだろう。
このへんは、だいぶ、なやましい。
まずはExcelのデータを作ってみた。
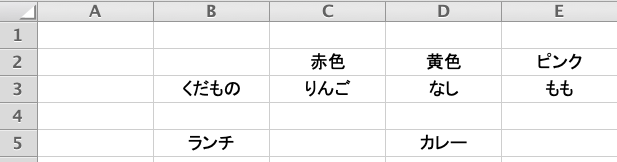
以下、Jupyter Notebook。
ExcelのデータをPandasで読み込む。
Excelデータは、作業ディレクトリの中に入れる。
import pandas as pd
table=pd.read_excel(‘fullna.xlsx’)
table
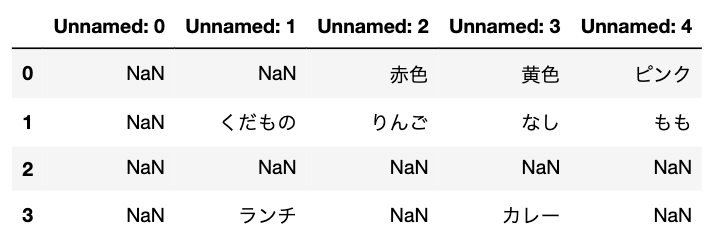
# ‘all’=> カンマではなく、シングル・コーテーション
# 引数 =>行は’all’あるいはhow=’all’.axis=0,
列はhow=’all’,axis=1
table.dropna(how=’all’).dropna(how=’all’,axis=1)
一列、一行のNaNが削除された。
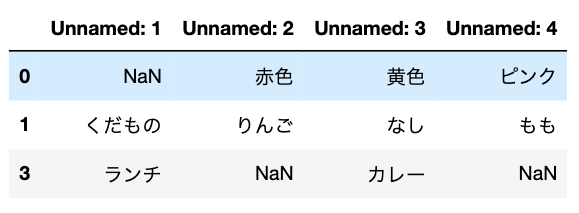
table.fillna(0)
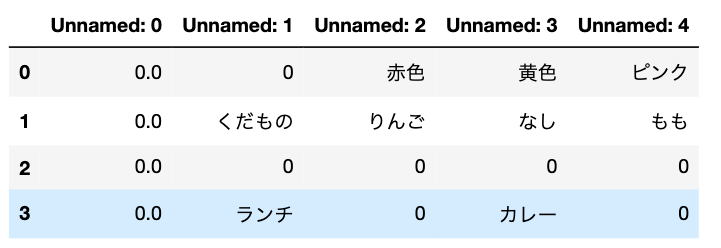
table.fillna(”)
